致力逼真角色,Meta为Codec Avatar解码提出硬件加速器框架F-CAD
2021-12-23
Meta一直致力于名为Codec Avatar的虚拟化身项目,从而帮助克服人与人之间,以及人与机会之间的物理距离挑战。借助突破性的3D捕获技术和人工智能系统,Codec Avatar可以帮助人们在未来快速轻松地创建逼真的虚拟化身,令虚拟现实中的社交联系变得如同现实世界般自然和常见。尽管虚拟角色多年来一直是游戏和应用的主要元素,但这家公司相信逼真的虚拟表现将会改变一切。
对于这个项目,团队早前已经多次分享过相关的研究进展。日前,Meta又通过名为《F-CAD: A Framework to Explore Hardware Accelerators for Codec Avatar Decoding》的论文介绍了用于为Codec Avatar解码探索硬件加速器的框架F-CAD。
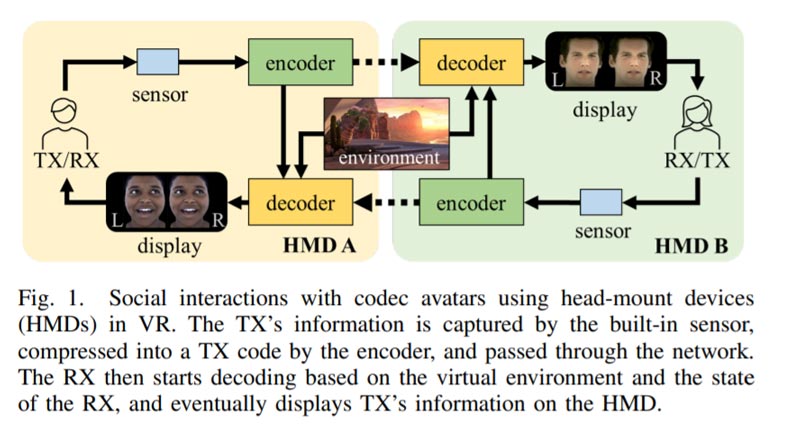
整个系统如图1所示,其中发射机(TX)的所有信息(例如扭曲的微笑和皱眉)将在到达接收机(RX)后进行编码、发送和解码,以生成用于高保真社交临场感的Codec Avatar。其中,解码器是最复杂的模块,占整个系统所需计算量的90%。如果没有有效的优化,它将轻易成为瓶颈,阻碍虚拟现实临场感的顺利实现。随着VR/AR耳机的普及,社会需求不断增加,对实时和高质量编解码器-化身解码的要求也越来越高。然而,在虚拟现实耳机上部署编解码器-化身解码器带来了重大挑战。
最先进的解码器属于计算和内存密集型,例如它可以包含超过13.6个GOP和720万个参数。同时,大多数头显只能提供有限的计算、内存和电源预算。为了防止晕动症,并提供实时响应以支持流畅用户交互,VR相较于非VR应用(30 FPS)要求更高的刷新率(90 FPS,甚至120 FPS)。
它要求硬件在不使用大batch size的情况下提供高吞吐量,因为收集batch输入的额外延迟可能无法满足实时要求。另外,新兴解码器开始采用具有定制神经网络层的复杂多分支DNN来生成Codec Avatar的不同组件,例如一个用于面部几何结构的分支和另一个用于纹理的分支,并且所述分支可能具有非常不同的要求。
上述独特的挑战令现有硬件加速器难以有效处理Codec Avatar解码器。另外,先进的商用SoC处理器(骁龙865)和学术界最近发布的两款DNN加速器(DNNBuilder和HybridDNN)未能提供令人满意的性能和效率。
针对这个问题,Meta和伊利诺伊大学厄巴纳-香槟分校的研究人员提出了F-CAD。这个全新的自动化工具用于加速具有复杂层依赖关系的多分支DNN。在论文中,团队关注Codec Avatar解码,将其作为F-CAD的一个重要和实际用例,并通过在资源预算下满足特定性能目标来提供优化的硬件加速器。
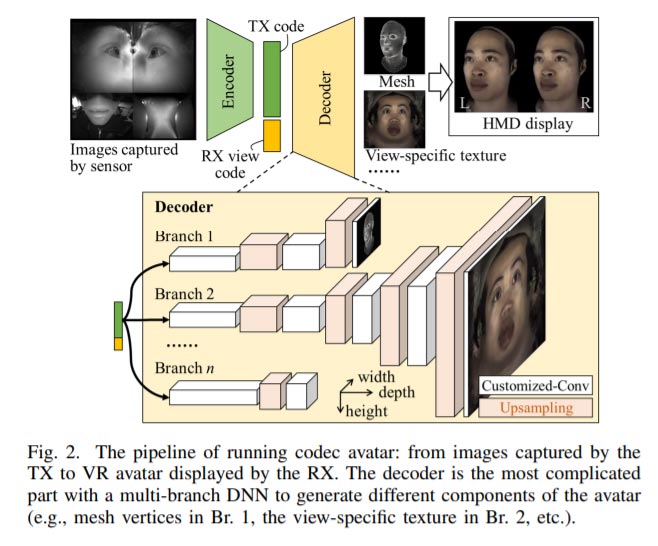
1.加速器设计挑战
Codec Avatar解码器独特的多分支功能和自定义层带来了推理过程中复杂的数据流和高计算和内存需求,这使得现有的DNN加速器难以应对。挑战包括巨大的和不均匀分布的计算和大量内存占用。对于资源有限,但以高吞吐量性能实时响应为目标的硬件加速器而言,这变得更具挑战性。团队从业界(骁龙865 SoC)和学术界(DNNBuilder,HybridDNN)中选择了三个现有加速器来加速Codec Avatar解码。
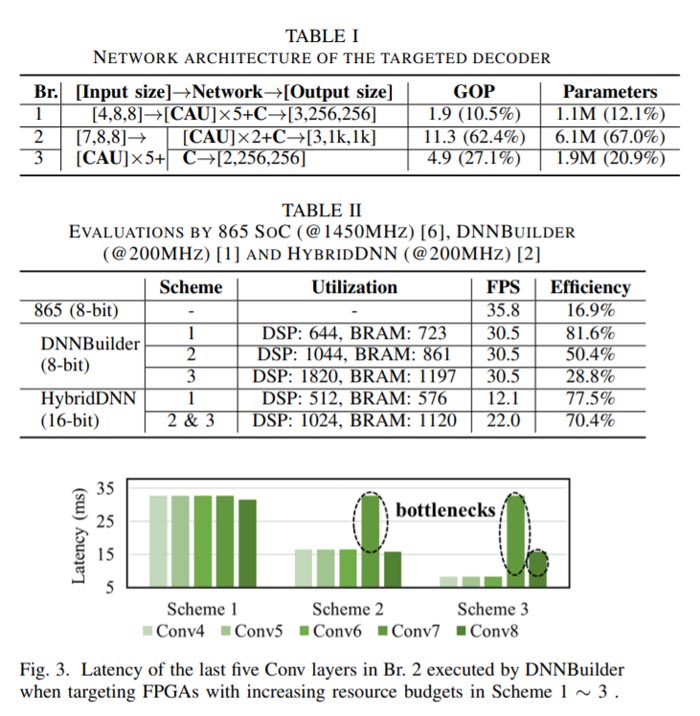
对于865 SoC,研究人员运行表I中所示的目标解码器。由于DNNBuilder和HybridDNN不支持定制的Conv,他们通过将定制的Conv替换为传统的Conv来创建模拟解码器,同时保持其余网络结构不变。模拟解码器具有高度相似的结构,但计算量减少了3.7%。这可以提供一定的洞察,以确定现有加速器设计的瓶颈。在评估过程中,团队使用了两个性能指标:FPS(表示吞吐量)和效率(实际和理论峰值吞吐量之间的比率,如等式3所示)。在下面的等式中,β表示一个multiplier在一个时钟周期内处理的操作数。

如表II所示,865 SoC只实现了35.8 FPS,整体效率勉强达到16.9%。DNNBuilder的吞吐量稍微更慢(30.5 FPS),但效率更高(81.6),而HybridDNN则数据则更差,吞吐量为12.1 FPS,而效率为(77.5%)。
2. F-CAD自动化设计流程
为了应对上述的问题,团队提出了F-CAD,通过它设计和开发用于多分支DNN的定制硬件加速器。如图4所示,F-CAD直接连接到流行的机器学习框架,并将开发的解码器模型作为输入,以实现更精细的定制。在Analysis步骤中,F-CAD不仅通过提取分层信息(例如层类型、层配置),而且通过提取分支信息(例如,分支编号、每个分支中的层数和层依赖关系)来开始分析目标网络。然后,profiler开始计算每一层的计算和内存需求,并提供关于分支需求的统计信息,以帮助将目标解码器映射到提出的加速器架构。输入同时包含资源预算和分支优先级,以设置资源界限。
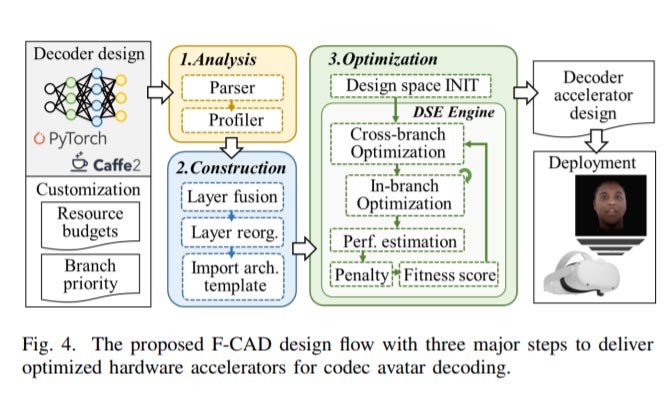
在Construction步骤中,执行层融合以减少层数量,其中轻量层(例如激活层)聚合到其相邻的主要层,例如控制计算或内存消耗的Conv-like和up-sampling层。然后分离具有共享部分的分支以创建单独的数据流,相应的层被重新组织并分配给计算需求最高的流。这个策略有助于避免硬件冗余,因为它不会实例化重复的硬件单元,并且会从共享分支创建一个清晰的临界流(计算量最大),并确保该流在Optimization步骤中得到足够的关注。
在融合和重组后,F-CAD分别根据层和分支编号沿X和Y维度导入和扩展拟议的弹性架构。最终,这将生成一个基本加速器,并在步骤3中进行优化。
在Optimization步骤中,首先确定加速器设计空间。解码器的层和分支构成了更高维的设计空间,因此搜索优化设计变得复杂。F-CAD引入了DSE引擎以利用跨分支和分支内优化。然后,将随机搜索应用于跨分支优化,探索跨分支的资源分配方案,并通过考虑设计空间和可用资源为每个分支寻找最佳加速器候选。最后,根据性能、效率和定制需求对候选加速器进行评估。DSE引擎最终通过迭代过程生成全局优化设计。
3. 加速器架构
A.基于层的多管道加速器范例
团队提出的加速器的设计范例如图5(A)所示。每个分支的输入以管道方式处理,并通过属于所述分支的所有管道阶段。对于具有共享部分的分支,按照层重组策略将相应的阶段分配给其中一个分支。例如,Branch2和3共享前两层,所以阶段1∼ 2被分配给Branch 2,而后续阶段分别执行。第2阶段的结果分布到两个不同的分支。研究人员同时采用了fine-grained管道设计,以降低管道初始延迟。
B.具有二维扩展能力的弹性架构
为了实现拟议的加速器范例,F-CAD引入了弹性架构,以便在二维以下灵活扩展加速器。在图5(b)中,所述弹性架构由基本架构单元组成,其布置在反映层重组结果的二维平面中,每个单元负责一个管道阶段。例如,在X轴之后的扩展意味着在这个分支中需要处理更多的阶段(本例为三个阶段),而沿Y轴的扩展表示在目标解码器中使用更多分支。在本例中,F-CAD生成一个加速器,其中有三条管道对应于Branch 1.∼ 3。
在基本架构单元内有三种类型的资源:计算(黄色区域)、片上内存(蓝色和绿色区域)和外部内存(红色区域)资源。上一层的输入特征图从左侧水平传递,其中一部分保存在输入缓冲区(InBuf)中,从而提供及时的数据供应。同时,DNN参数从外部存储器中提取,并按照计算顺序存储在权重缓冲区(WeightBuf)中。
为满足不同层阶段的各种需,每个基本架构单元都是高度可配置。它支持建议的3D并行性,包括沿输出和输入通道的两个展开因子(内核并行因子kpf和通道并行因子cpf)和输入特征图的分区因子(H分区)。配置后,计算引擎的H分区数被实例化,每个引擎包含kpf流程元素(PE)来处理计算。提出的基本架构单元同时允许定制输入特征(DW)、权重(WW)和外部存储器总线(MW)的位宽度。
C.具有3D并行性的基本架构
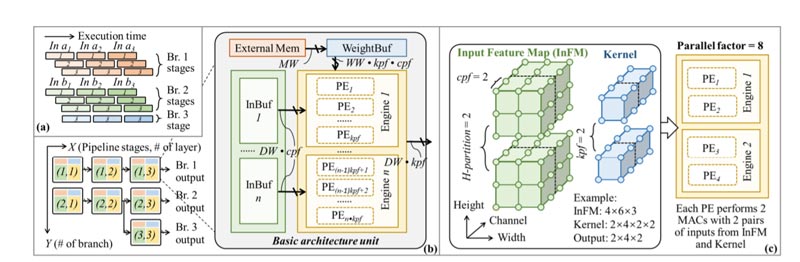
图5(C)提供了拟议3D并行性的详细说明。假设一个具有4×6×3输入特征映射(InFM)和两个4×2×2内核的Conv类层。最大输入并行因子为cpf max=4,最大输出并行因子为kpf max=2,因为该层包含四个可并行处理的输入通道和两个输出通道。在这种情况下,将输入和输出并行因子配置为2(cpf=kpf=2),因此每个计算引擎将实例化两个PE,每个PE并行执行两个MAC。由于来自输入/输出通道的并行性可能不足以用于Codec Avatar解码,研究人员通过沿高度维度划分InFM来添加一个额外的并行性。因此,所有InFM子部分都可以并行处理。本例的总并行因子为cpf×kpf×H-partition=8,实例化了四个PE。
在实验测试中,研究人员针对三个嵌入式FPGA平台(Xilinx Z7045、ZU17EG和ZU9CG)演示F-CAD加速Codec Avatar解码的能力和可扩展性。由于目标平台是FPGA,团队将资源预算Cmax和Mmax设置为目标FPGA中的可用DSP和BRAM,将BWmax设置为DDR3内存带宽。所有平台的时钟频率均设置为200MHz。
表I中描述了目标解码器,其中定制的batch size{1,2,2}对应于Branch 1.∼ 3。大多数VR虚拟化身应用都会考虑这种定制,其中Branch 2和3需要渲染两眼都能看到镜面反射效果的两个HD纹理,而Branch 1仅输出一个可由双眼共享的面部几何图形。
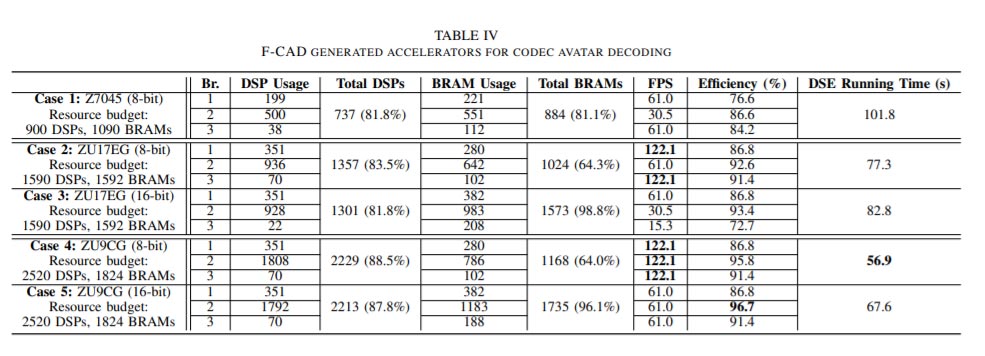
表IV列出了实验结果,其中F-CAD按照建议的弹性架构生成了五个加速器。为了评估搜索速度,团队对每种情况执行10次独立搜索,其中N=20(意味着搜索包含20次迭代)和P=200(意味着初始化了200个候选资源分布),所有搜索都使用2.6 GHz的Intel i7 CPU在几分钟内收敛。收敛的平均迭代次数为9.2次(最小值:6.8;最大值:13.6)。最终,F-CAD通过考虑定制和资源约束生成优化设计。特别是,案例4的加速器达到最高122.1 FPS,完全满足VR要求;而案例5的加速器提供了最高的效率峰值96.7%。
团队将F-CAD生成的加速器与表V中的现有设计进行比较,以相同的ZU9CG FPGA为目标,配备2520个DSP和1824个BRAM。DNNBuilder的性能和效率受到并行性不足的限制,因此分配的资源没有得到充分利用。
另一方面,HybridDNN无法分配更多的DSP,并且留下超过一半的可用DSP未分配。原因是coarse-grained配置需要两倍大小的加速器实例才能继续扩展,但BRAM预算不足,成为瓶颈。在研究人员的设计中,F-CAD在相同的资源预算下提供最高的FPS和效率。与DNNBuilder相比,其实现了4.0倍更高的吞吐量和62.5%更高的效率。与HybridDNN相比,在运行16位模型时,其只需多分配2.2倍的DSP,就能提供2.8倍的吞吐量,效率提高21.2%。
总的来说,团队在论文中介绍了F-CAD。为了解决特殊的DNN结构和苛刻的性能要求所带来的独特挑战,研究人员提出了支持多分支DNN的可扩展弹性架构和高度可配置的基本架构单元,以提供灵活和可扩展的并行处理。
然后,其引入了一个多分支动态设计空间来描述硬件配置,并引入了一个高效的DSE引擎,通过考虑各种定制约束和可用资源预算来探索优化的加速器。在实验中,F-CAD提供了非常高的吞吐量和效率,峰值达到122.1 FPS和91.6%。与最先进的加速器相比,在针对同一FPGA时,F-CAD的吞吐量分别比DNNBuilder和HybridDNN高4.0倍和2.8倍,效率分别高62.5%和21.2%。
原文来自https://news.nweon.com/92811

VR头显真的需要到180Hz吗?
2020-05-13

全球首次!圆周率科技5G+VR直播带你“云登顶”世界屋脊
2020-05-28

前HTC CEO周永明发布了一体式VR头显Mova
2020-05-27

数字化虚拟景区:未来必然趋势
2020-05-15

iPad Pro:HoloLens 2第三人称视角的最佳解决方案
2020-05-13